MapReduce Architecture and Job Execution Flow
Verified Concept Article • Factual Traceability Enabled
Summary OverviewMapReduce processes a job by splitting input data into blocks, executing parallel mapper tasks on DataNodes, shuffling intermediate results, and aggregating them with reducers under the coordination of JobTracker and TaskTrackers.
Overview of the MapReduce Architecture
The Hadoop MapReduce framework sits atop the Hadoop Distributed File System (HDFS), whose core components are the NameNode—which maintains the global namespace and metadata—and multiple DataNodes that store the actual data blocks. When a user submits a job, the complete input file is treated as a single logical unit, but HDFS automatically divides it into fixed‑size blocks. Each block becomes the unit of work for a mapper task. This design enables data locality: mapper tasks are launched on the same DataNode that holds the corresponding block, minimizing network traffic.
Core Components and Their Roles
- JobTracker: The central coordinator that receives job submissions, divides the job into map and reduce tasks, and assigns them to available TaskTrackers. It also monitors progress, handles failures, and determines when the job is finished.
- TaskTracker: A daemon running on each DataNode that launches and monitors individual map or reduce tasks. It periodically reports status (heartbeat) back to the JobTracker, allowing the system to detect stalled or failed tasks.
- Mapper: Executes the user‑defined map function on each input split, producing intermediate key‑value pairs. The mapper runs directly on the DataNode holding the split, leveraging data locality as described in the source bullet points.
- Reducer: After the map phase, the framework performs a shuffle and sort operation that groups all values associated with the same key. Reducer tasks then process each key group to generate the final output.
Job Execution Flow
- Job Submission: A client submits a MapReduce job to the JobTracker, providing the input path, output path, and the map/reduce classes.
- Input Splitting: The JobTracker queries the NameNode to obtain block locations. It creates input splits that map one‑to‑one with HDFS blocks, turning each split into a map task.
- Task Allocation: The JobTracker assigns each map task to a TaskTracker on the DataNode that stores the relevant block, achieving the data‑local execution highlighted in the sources.
- Map Phase: TaskTrackers launch mapper processes. As mappers emit intermediate key‑value pairs, the framework writes them to local disk and begins the shuffle—transferring data to the appropriate reducer nodes.
- Shuffle and Sort: Intermediate data is sorted by key and transferred across the network to reducer nodes. This step is implicit in the diagram of "MapReduce Job Processing" from the source images.
- Reduce Phase: Reducer tasks, also managed by TaskTrackers, read the sorted groups, apply the user‑defined reduce function, and write final results back to HDFS.
- Completion Reporting: Once all map and reduce tasks signal successful completion, the TaskTrackers send a final heartbeat to the JobTracker. The JobTracker marks the job as finished and reports the status, mirroring the source description of job completion.
Fault Tolerance and Monitoring
Both JobTracker and TaskTrackers continuously exchange status messages. If a TaskTracker fails to send a heartbeat, the JobTracker assumes the task has failed and re‑assigns it to another node, ensuring reliability without manual intervention. This monitoring loop is a cornerstone of Hadoop’s robustness.
Summary of the Flow
The MapReduce architecture orchestrates a seamless pipeline: HDFS provides block‑level data placement, the JobTracker schedules tasks, TaskTrackers execute mappers and reducers on DataNodes, and the shuffle‑sort phase bridges the two phases. The coordinated status exchanges guarantee that a job is declared complete only after every constituent task has successfully finished, aligning with the process illustrated in the referenced figures.
Visual References from Cited Pages
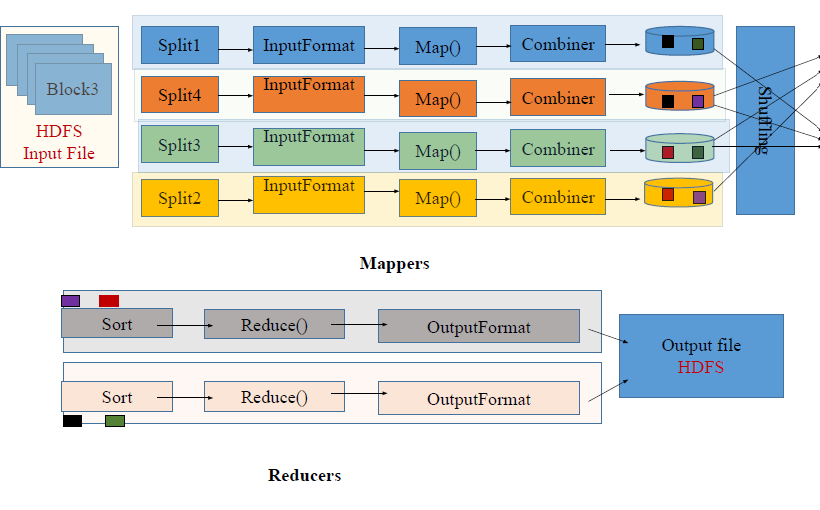
Figure 1: Image page 14, image 1Source: Hadoop.pdf (Page 14)
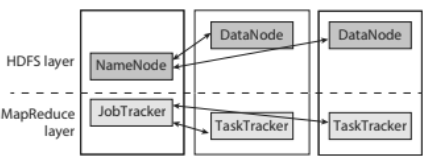
Figure 2: Image illustrating the MapReduce architecture, including HDFS Layer and task processing.Source: Hadoop.pdf (Page 13)
Related Topics
Incoming Backlinks
Other pages in this wiki that link back to the current topic.