HDFS Write and Read Data Flow Architecture
Verified Concept Article • Factual Traceability Enabled
Summary OverviewThe HDFS write and read data flow architectures define how clients interact with the NameNode and DataNodes to store and retrieve block replicas efficiently.
Overview of HDFS Data Flow
The Hadoop Distributed File System (HDFS) separates metadata management from block storage. The NameNode maintains the namespace and block‑to‑DataNode mappings, while DataNodes store the actual byte blocks. Both write and read operations follow a coordinated sequence that leverages replication, pipelining, and checksum verification to ensure reliability and high throughput.
Write Data Flow Architecture
When a client creates or appends a file, the following steps occur:
- Metadata Request – The client contacts the NameNode to create a new file entry. The NameNode returns a list of DataNodes for each block, typically three, to satisfy the default replication factor.
- Pipeline Formation – The client establishes a TCP connection to the first DataNode in the list. That DataNode, in turn, opens a connection to the second, and so on, forming a write pipeline (see !Write pipeline diagram).
- Streaming and Replication – The client streams the block data to the first DataNode. Each DataNode writes the received bytes to its local disk and forwards the data downstream. This simultaneous forwarding creates the required replicas without additional network hops.
- Checksum Generation – As data passes through the pipeline, each DataNode computes a checksum for every packet. The checksum is sent back to the client as an acknowledgment, enabling early detection of corruption.
- Acknowledgment Propagation – Once the last DataNode stores the block, it sends an acknowledgment upstream. The client receives a final confirmation only after all replicas have been persisted, ensuring strong consistency.
- Block Report – Periodically, each DataNode sends a block report to the NameNode, updating it on the newly created replicas.
The write architecture emphasizes pipeline parallelism and fault tolerance: if a DataNode fails, the client can re‑establish the pipeline with alternative nodes based on the NameNode’s updated block map.
Read Data Flow Architecture
Reading data mirrors the write process but in reverse order:
- Block Location Lookup – The client queries the NameNode for the locations of the desired block. The NameNode returns a prioritized list, often favoring the closest replica (see !Read flow diagram).
- Direct DataNode Connection – The client connects to the first DataNode in the list and begins streaming the block. If the client requests a large file, it may open parallel streams to multiple DataNodes, improving throughput.
- Checksum Verification – As packets arrive, the client validates the embedded checksums. A mismatch triggers a re‑read from another replica.
- Pipeline for Large Reads – For very large files, HDFS can form a read pipeline where the client pulls data from one DataNode while the next block is prefetched from another, reducing latency.
- Failure Handling – If a DataNode becomes unreachable, the client automatically fails over to the next replica in the list, ensuring uninterrupted reads.
Key Takeaways
- Pipelining is central to both write and read paths, allowing simultaneous data transfer and replication.
- Checksum mechanisms guarantee data integrity across the network.
- The NameNode orchestrates block placement and location, while DataNodes handle the heavy‑lifting of storage and transfer.
- Fault tolerance is built‑in: both operations can recover from node failures without client intervention.
Together, these architectures enable HDFS to provide scalable, reliable, and high‑performance storage for big‑data workloads.
Visual References from Cited Pages
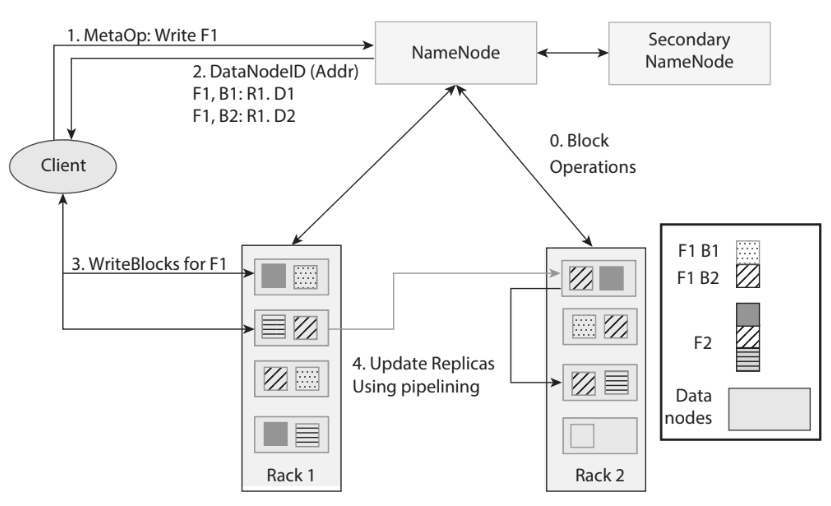
Figure 1: Image illustrating the HDFS write architecture.Source: Hadoop.pdf (Page 8)
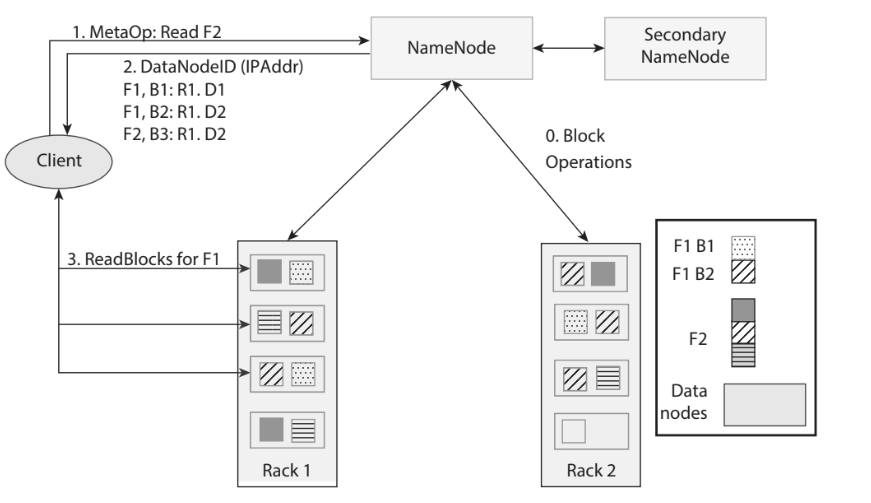
Figure 2: Image page 11, image 1Source: Hadoop.pdf (Page 11)
Related Topics
Incoming Backlinks
Other pages in this wiki that link back to the current topic.