Hadoop and the Burger Analogy for Distributed Data Processing
Verified Concept Article • Factual Traceability Enabled
Summary OverviewThe burger analogy illustrates Hadoop’s distributed data processing by likening each architectural element to a layer of a burger, making complex concepts accessible.
Introduction
The Hadoop ecosystem, a cornerstone of big‑data processing, can appear abstract to newcomers because it combines distributed storage (HDFS), parallel computation (MapReduce, YARN), and fault‑tolerant design. Educators therefore employ visual metaphors to bridge the gap between theory and intuition. One widely cited metaphor is the burger analogy, depicted on page 17 of the source material. The image shows a fully assembled burger, each ingredient representing a distinct Hadoop component. By treating the data‑processing pipeline as a familiar sandwich, the analogy demystifies how large data sets are broken into pieces, processed concurrently, and recombined into a final result.
The Burger Analogy Explained
In the illustration, the bun, patty, lettuce, cheese, tomato, and condiments are arranged in a fixed order. Each layer corresponds to a stage in the Hadoop workflow:
- Bottom bun – the client or application that submits a job, analogous to the plate that supports the entire sandwich.
- Patty – the raw data stored in HDFS blocks across the cluster; just as a patty provides the core substance, the data blocks provide the substantive content for processing.
- Lettuce and tomato – the Map phase, which spreads the data across many nodes, adding freshness and variety much like vegetables add texture.
- Cheese – the shuffle and sort operations that bind the map output to the reduce input, melting the disparate pieces into a cohesive whole.
- Top bun – the final output delivered to the user, sealing the result and presenting it in a ready‑to‑consume form.
The visual cue of stacking ingredients mirrors Hadoop’s layered architecture: data ingestion, distribution, transformation, and delivery. The analogy also highlights parallelism; each ingredient can be prepared independently (e.g., grilling multiple patties) before assembly, just as Hadoop runs map tasks on many nodes simultaneously.
Mapping Analogy to Hadoop Components
The broader Hadoop framework, described in the sub‑article hadoop/fundamentals-of-hadoop-architecture" class="text-[#6b38d4] font-semibold hover:underline">Fundamentals of Hadoop Architecture</a>, consists of three primary subsystems:
- HDFS (Hadoop Distributed File System) – stores data in replicated blocks; in the burger metaphor, these blocks are the “patty” that is duplicated across the cluster for fault tolerance.
- YARN (Yet Another Resource Negotiator) – manages cluster resources and schedules containers; it functions like the kitchen staff that allocates burners and griddles to cook each ingredient.
- MapReduce (or alternative engines such as Spark) – performs the actual computation; this is the cooking process that transforms raw ingredients (data) into a finished dish (result).
By aligning each subsystem with a burger component, learners can visualize how the client (bottom bun) hands off data to HDFS (patty), YARN orchestrates the parallel execution (lettuce/tomato preparation), and MapReduce fuses the outcomes (cheese) before the top bun presents the final product.
Educational Value and Relation to Other Articles
The hadoop/burger-analogy-for-distributed-data-processing" class="text-[#6b38d4] font-semibold hover:underline">Burger Analogy for Distributed Data Processing</a> sub‑article expands on the visual metaphor, providing step‑by‑step explanations of how data flows through the system. It complements the more technical hadoop/fundamentals-of-hadoop-architecture" class="text-[#6b38d4] font-semibold hover:underline">Fundamentals of Hadoop Architecture</a> article by offering a low‑barrier entry point for novices, while still preserving the precise relationships among components. In pedagogical practice, the analogy is used in lectures, tutorials, and documentation to:
- Reinforce the concept of data partitioning and replication.
- Illustrate the independence of map tasks and the necessity of a shuffle‑sort phase.
- Emphasize fault tolerance (extra lettuce or tomato can replace a missing ingredient without ruining the burger).
Because the analogy is visual, it also serves as a mnemonic device: remembering the order of ingredients helps recall the order of processing stages.
See Also
- hadoop/fundamentals-of-hadoop-architecture" class="text-[#6b38d4] font-semibold hover:underline">Fundamentals of Hadoop Architecture</a> – detailed technical description of HDFS, YARN, and computation engines.
- hadoop/burger-analogy-for-distributed-data-processing" class="text-[#6b38d4] font-semibold hover:underline">Burger Analogy for Distributed Data Processing</a> – focused discussion on the metaphor, including variations for Spark and Flink.
- MapReduce Programming Model – in‑depth guide to writing map and reduce functions.
- Hadoop Ecosystem Projects – overview of related tools such as Hive, Pig, and HBase.
The burger analogy thus functions as a bridge between abstract distributed‑system theory and everyday experience, enabling learners to grasp Hadoop’s core principles with a concrete, appetizing image.
Visual References from Cited Pages
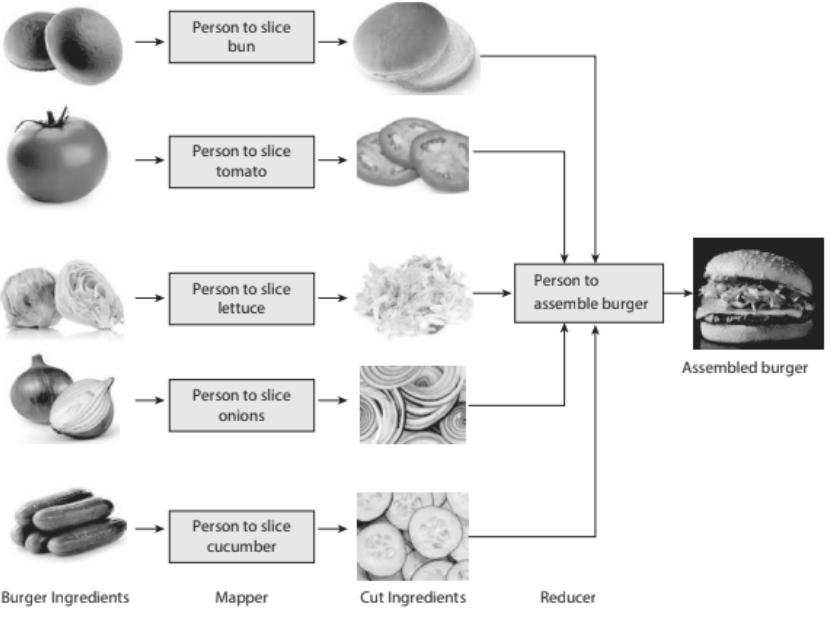
Figure 1: Image illustrating the Burger AnalogySource: Hadoop.pdf (Page 17)
Subtopics & Sections
The burger analogy illustrates how distributed data processing pipelines decompose a complex task into layered, parallelizable steps analogous to assembling a burger.
The Hadoop architecture combines a distributed storage layer (HDFS) with a parallel processing framework (YARN/MapReduce) to enable scalable, fault‑tolerant data analytics.
Related Topics
Incoming Backlinks
Other pages in this wiki that link back to the current topic.
hadoop
A comprehensive overview of Hadoop’s distributed storage and processing architecture, illustrating its core components, data movement strategies, replication mechanisms, job execution flow, and practical examples such as the Word Count application, while using analogies to simplify complex concepts.
Fundamentals of Hadoop Architecture
The Hadoop architecture combines a distributed storage layer (HDFS) with a parallel processing framework (YARN/MapReduce) to enable scalable, fault‑tolerant data analytics.
Burger Analogy for Distributed Data Processing
The burger analogy illustrates how distributed data processing pipelines decompose a complex task into layered, parallelizable steps analogous to assembling a burger.