Fundamentals of Hadoop Architecture
Verified Concept Article • Factual Traceability Enabled
Summary OverviewThe Hadoop architecture combines a distributed storage layer (HDFS) with a parallel processing framework (YARN/MapReduce) to enable scalable, fault‑tolerant data analytics.
Core Components of Hadoop
Hadoop is built around two foundational subsystems: the Hadoop Distributed File System (HDFS) for reliable, high‑throughput storage, and a resource‑management/processing engine (originally MapReduce, now YARN) that schedules computation across a cluster. Together they form a layered architecture where data locality and fault tolerance are integral design goals.
HDFS: Distributed Storage Layer
HDFS follows a master‑worker model. The NameNode acts as the master metadata server, maintaining the namespace hierarchy, file‑to‑block mappings, and block replication policies. DataNodes are the worker processes that store actual data blocks on local disks. Files are split into large blocks (typically 128 MB) and each block is replicated—commonly three times—across distinct DataNodes. This replication ensures durability: if a DataNode fails, the NameNode directs other nodes to recreate the lost replicas from remaining copies.
The architecture also includes a Secondary NameNode (or more modern CheckpointNode) that periodically merges the edit log with the filesystem image, preventing the edit log from growing without bound. Though not a standby NameNode, it aids in recovery and reduces startup time.
YARN: Resource Management and Scheduling
YARN (Yet Another Resource Negotiator) decouples resource allocation from job execution. The ResourceManager runs on a master node and arbitrates cluster resources among multiple applications. For each application, the ResourceManager launches an ApplicationMaster, which negotiates containers (bundles of CPU and memory) on specific nodes. On the worker side, NodeManagers supervise container life cycles, monitor health, and report resource availability back to the ResourceManager.
This separation allows Hadoop to support diverse processing models—MapReduce, Spark, Tez—by simply providing a compatible ApplicationMaster, making the platform more flexible than the original monolithic MapReduce scheduler.
Data Locality and Fault Tolerance
A hallmark of Hadoop’s design is moving compute to the data. When the ResourceManager assigns containers, the scheduler prefers nodes that already host the required HDFS blocks, reducing network traffic and improving throughput. If a node or container fails, YARN automatically re‑requests resources and the ApplicationMaster can restart the failed task on another node, leveraging HDFS’s replicated blocks.
Ecosystem Integration
Beyond core storage and processing, Hadoop’s architecture provides extensibility points. ZooKeeper offers coordination services for distributed applications, while HBase and Hive sit atop HDFS to deliver NoSQL and SQL‑like interfaces, respectively. These components interact through the same NameNode/DataNode and YARN services, preserving the unified management model.
Summary of Architectural Principles
- Scalability: Horizontal scaling by adding commodity nodes.
- Fault tolerance: Automatic replication and task re‑execution.
- Data locality: Scheduling computation where data resides.
- Modularity: Separate layers (storage, resource management, execution) enable plug‑in of new processing engines.
Understanding these fundamentals equips practitioners to design, configure, and troubleshoot Hadoop clusters, ensuring that large‑scale data workloads are processed efficiently and reliably.
Visual References from Cited Pages
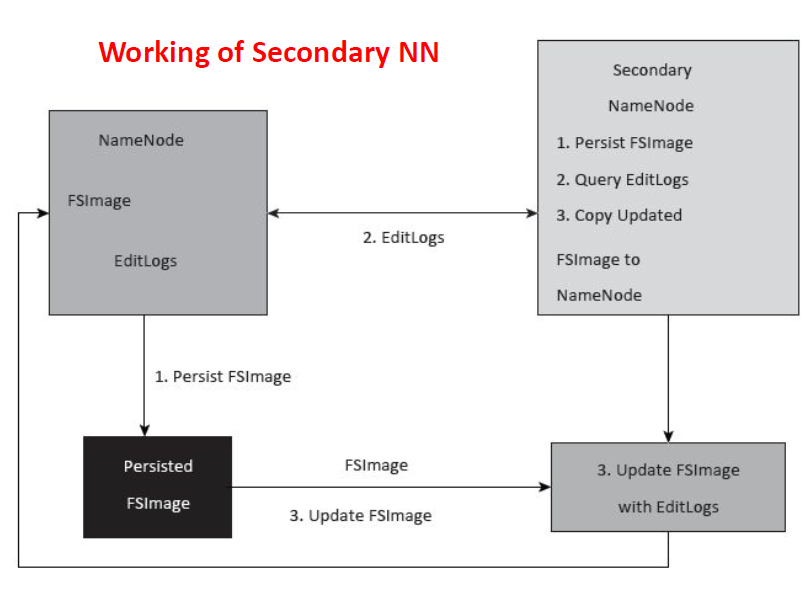
Figure 1: Image page 6, image 1Source: Hadoop.pdf (Page 6)
Related Topics
Incoming Backlinks
Other pages in this wiki that link back to the current topic.