Burger Analogy for Distributed Data Processing
Verified Concept Article • Factual Traceability Enabled
Summary OverviewThe burger analogy illustrates how distributed data processing pipelines decompose a complex task into layered, parallelizable steps analogous to assembling a burger.
Overview of the Burger Analogy
The burger analogy is a pedagogical tool used to explain the principles of distributed data processing, especially in the context of Hadoop's MapReduce framework. By comparing a data workflow to the construction of a burger, the analogy conveys how large, monolithic tasks can be broken down into manageable, parallel components that are later combined to produce a final result. The visual representation on page 17 (see the repeated image) typically shows a burger with distinct layers—bun, patty, lettuce, cheese, sauce—each symbolizing a stage in the processing pipeline.
Mapping the Burger Layers to Processing Stages
- Bottom Bun – Data Ingestion
The bottom bun represents the raw input data that is ingested into the system. In Hadoop, this corresponds to data stored in HDFS (Hadoop Distributed File System) or other storage layers. Just as the bun provides a stable foundation for the burger, the ingestion layer ensures that data is reliably partitioned across the cluster.
- Patty – Map Phase
The patty is the core of the burger, analogous to the map function in MapReduce. Each distributed node receives a slice of the input data and applies the map operation, generating intermediate key‑value pairs. This step is embarrassingly parallel, much like cooking multiple patties simultaneously on a grill.
- Lettuce and Cheese – Shuffle and Sort
After the patty, the lettuce and cheese layers symbolize the shuffle and sort phases. Intermediate data produced by the map tasks is redistributed across the network so that all values associated with the same key converge on the same reducer. The ordering (sort) prepares the data for deterministic reduction, akin to arranging toppings in a consistent order for each burger.
- Sauce – Reduce Phase
The sauce embodies the reduce function, where aggregated results are computed. Each reducer processes the grouped key‑value pairs, applying business logic—summing counts, concatenating strings, or performing statistical calculations. The sauce binds the components together, just as reduction synthesizes the final output.
- Top Bun – Output and Consumption
The top bun caps the burger, representing the final output written back to storage or presented to downstream applications. In Hadoop, this may be a file in HDFS, a database load, or a real‑time feed. The completed burger is ready to be served, mirroring how processed data becomes actionable insight.
Educational Benefits
The burger analogy simplifies abstract concepts such as data partitioning, parallel execution, and data aggregation, making them accessible to non‑technical audiences. It emphasizes the modular nature of distributed processing—each layer can be optimized independently, yet the overall structure remains coherent.
Limitations and Extensions
While the analogy captures the linear flow of MapReduce, modern Hadoop ecosystems incorporate additional components (e.g., YARN for resource management, Spark for in‑memory computation) that extend beyond the simple burger model. Nevertheless, the core idea of layering and parallelism remains a useful mental model for understanding distributed data pipelines.
Conclusion
By visualizing distributed data processing as the assembly of a burger, educators and practitioners can convey complex architectural concepts in an intuitive, memorable way. The layers illustrate how raw data is transformed, shuffled, reduced, and finally delivered as a cohesive result, mirroring the satisfaction of enjoying a well‑constructed burger.
Visual References from Cited Pages
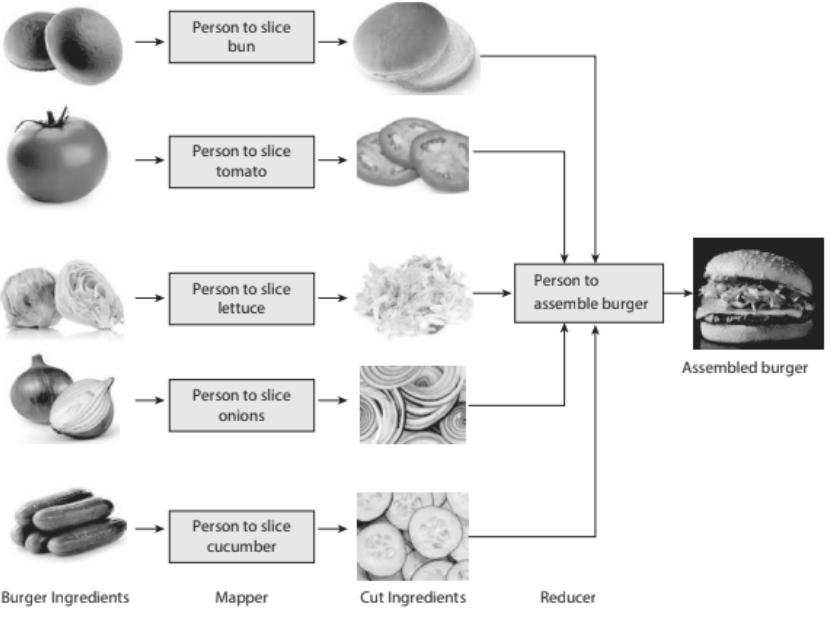
Figure 1: Image illustrating the Burger AnalogySource: Hadoop.pdf (Page 17)
Related Topics
Incoming Backlinks
Other pages in this wiki that link back to the current topic.