Managing Data in Motion vs. Persistent Data
Verified Concept Article • Factual Traceability Enabled
Summary OverviewManaging data in motion focuses on secure, timely transformation and delivery of streaming data, while persistent data management emphasizes layered storage security and structural consistency.
Overview
Data integration architectures distinguish between two fundamental states of information: persistent data, which resides in databases, data lakes, or warehouses, and data in motion, which traverses networks, applications, and organizational boundaries. Both states require careful handling, yet their priorities, security models, and integration techniques differ markedly. Understanding these differences is essential for architects designing end‑to‑end pipelines that keep data trustworthy, available, and usable.
Data in Motion vs. Persistent Data
Persistent data is characterized by long‑term storage and a focus on the structure of the data model. As the sources note, the primary concern is "how to associate, map, and transform data between different systems" (Source 1). In contrast, data in motion concerns the flow of information. It involves managing the data that travels between systems, applications, data stores, and even organizations (Source 3). The emphasis shifts from static schema to ensuring that data arrives at the right place, at the right time, and in the right format.
Security and Access Considerations
For persistent data, security is implemented in layers: physical, network, server, application, and data‑store controls (Source 1). This multilayered approach protects data at rest and governs who can read or write to the storage.
Data in motion demands additional safeguards because the data is exposed during transmission. Encryption and decryption are applied to protect data in transit, preventing unauthorized interception (Source 1). While layered defenses still apply, the transient nature of the data adds a critical need for real‑time cryptographic controls and secure transport protocols.
Integration Patterns and Complexity
Both data states are addressed through various integration techniques (Source 5). Batch data integration groups records and moves them periodically (e.g., daily or weekly). This asynchronous, point‑to‑point approach is ideal for large‑scale conversions and loading snapshots into data warehouses (Source 10).
Real‑time integration—often called streaming or event‑driven integration—handles data in motion, delivering updates instantly to downstream systems. It supports use cases such as fraud detection, inventory management, and personalized recommendations where latency must be minimal.
Big data integration and data virtualization further blur the line between motion and persistence by allowing heterogeneous sources to be accessed virtually, without moving the data physically, while still providing a unified view for analytics.
Governance, Quality, and Trust
Regardless of state, data must be trusted. Governance processes define policies for data quality, lineage, and stewardship (Source 3). For data in motion, these processes ensure that transformations preserve meaning and that the data arriving at its destination complies with business rules. For persistent data, governance focuses on schema evolution, archival policies, and compliance with regulatory requirements.
Conclusion
Managing data in motion versus persistent data involves distinct but complementary concerns. Persistent data management prioritizes layered security and structural consistency, whereas data in motion emphasizes secure, timely delivery and format alignment. Effective integration architectures blend batch, real‑time, and virtualization techniques, underpinned by robust governance, to create a cohesive data ecosystem that serves both static storage needs and dynamic, streaming demands.
Visual References from Cited Pages
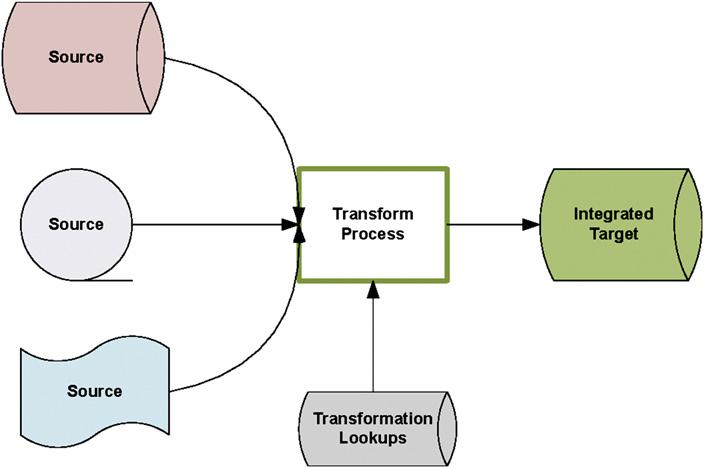
Figure 1: Illustration of data transformation processSource: DataIntegration.pdf (Page 14)
Related Topics
Incoming Backlinks
Other pages in this wiki that link back to the current topic.