Data Integration
Interactive structured knowledge system generated from source documents.
Wiki Overview
Overview
Data integration is the disciplined process of bringing together disparate data assets—whether streaming in motion, stored persistently, or residing in unstructured repositories—into a common format that supports unified access and analysis. As the source evidence explains, integration involves moving data around the organization, transforming it into a shared representation, and even migrating it between systems. The overarching goal is to give users a homogeneous logical view of data that is physically distributed across heterogeneous sources, thereby satisfying complex information needs that no single system can meet on its own.
Foundations and Lifecycle of Data Integration
The development of any integration solution follows a well‑defined lifecycle. Early scoping establishes high‑level requirements, identifies source and target systems, and outlines the data requirements that will shape the design. Subsequent profiling of the actual data uncovers nuances that can dramatically affect the solution architecture, while periodic proving ensures that the interfaces remain accurate once in production. Business knowledge and expertise are woven throughout this lifecycle, ensuring that technical decisions align with organizational objectives. This structured approach is essential for managing the natural complexity of data interfaces and for enabling advanced capabilities such as big‑data processing and virtualization.
Managing Interface Complexity Through Abstraction
Point‑to‑point connections between systems quickly become untenable as the number of applications grows, a problem highlighted in the article Point-to-Point Interface Complexity in System Integration. To counteract this combinatorial explosion, Managing Interface Complexity Through Abstraction Hierarchies proposes layered models that hide lower‑level technical details behind unified interfaces. Similarly, Abstraction Levels in Interface Design describe how each stratum progressively abstracts away implementation specifics, allowing developers to interact with heterogeneous environments through a single, coherent API. These hierarchies reduce maintenance overhead and improve scalability, especially when combined with middleware or common data storage patterns.
Visual References from Cited Pages

Figure 1: Illustration of the integration problem showing a unified global data model across heterogeneous data sourcesSource: DataIntegration.pdf (Page 20)
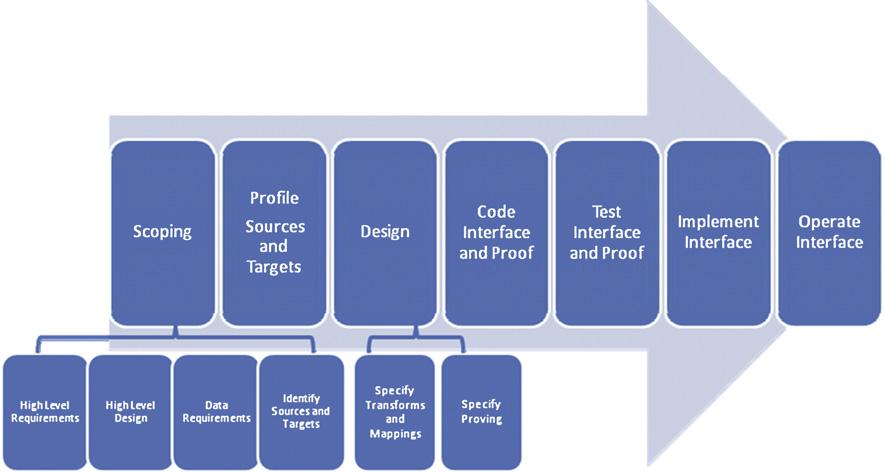
Figure 2: Data Integration Life Cycle illustrationSource: DataIntegration.pdf (Page 42)
What You'll Learn
- Data Integration Architectures, Techniques, and Lifecycle Management
- Data Schema Integration Illustrated with ORM and ER Models
- Managing Interface Complexity Through Abstraction Hierarchies
- Personalized Web Portals for Uniform Data Access
Main Topics & Knowledge Domains
Data Integration Architectures, Techniques, and Lifecycle Management
Data integration architecture orchestrates diverse techniques—batch, real‑time, big‑data, and virtualization—to unify persistent and motion data throughout a managed lifecycle.
Data Schema Integration Illustrated with ORM and ER Models
Data schema integration aligns heterogeneous ER and ORM models into a unified representation to support coherent data access across systems.
Managing Interface Complexity Through Abstraction Hierarchies
Abstraction hierarchies reduce the combinatorial growth of point‑to‑point interfaces by providing layered, unified models that simplify data integration across heterogeneous systems.
Personalized Web Portals for Uniform Data Access
Personalized web portals provide a uniform, user‑centric entry point to heterogeneous data sources by combining portal technology, web‑mining‑derived user profiles, and integration architectures such as mediated query systems and data warehouses.